
Welcome to the first report from Trend Monitor 2025/2026. We start with a brief dive-in into the fundamentals and present capabilities and limitations of large language models. We also detail how we used human-guided multi-agent systems to discover trends, and to score them. We then discuss the results of our trend survey, and of the scoring of trends on uncertainty and impact by experts and AI agents. Finally, we present our thoughts on implementing agentic systems, and next steps in the Trend Monitor project.
Executive summary
A large language model is an artificial intelligence system that uses deep learning techniques—specifically, neural networks called transformers—to process, understand, and generate human language at scale.
An agent is a specialized instance of a LLM, created to perform a very specific task. Agents are the center of the "agentic future" where they act as completely autonomous entities that can set their own goals, make decisions about when and how to act; and learn from experience in a meaningful, transferable way. Given the current limitations of LLMs’ semantic memory and associative learning capabilities, this future seems somewhat distant.
In this report, we elucidate that it is possible to productively apply generative AI, even with its present limitations. We use human-guided multi-agent systems to identify STEEP trends that may shape the next decade for aviation, and to score these trends on uncertainty and impact. In comparison to seemingly autonomous systems, human-guided ones require periodic human intervention, much more explicit prompting and relatively elongated development-timelines. In our experience, however, these systems have significant advantages - they result in more relevant responses, thanks to context and knowledge defined by experts; they result in more factual responses through the combination of agentic validation and human corroboration; they enable faster adaptability, through iterative manual modification of agents’ roles and addition or deletion of agents; and reduce the risk of systemic failure, thanks to the possibility of human verification of interim results.
Agentic trend-identification shows itself to be effective and efficient. Agents were able to significantly cover the relevant trendspace, with all except two expert-suggested trends already being identified by the agents. The trend-scoring activity demonstrated the semantic-associative memory limitations of LLMs. In this scenario, we made the practical choice of achieving contextual grounding via comparative scoring aided by human guidance. Comparing the agents’ and expert scores, we saw some interesting phenomenon; such as the correlation between the deviation between agent and expert scores, and the relative deviation among the expert-scores.
While agentic applications are currently attracting significant investment, misplaced expectations may lead to a rude awakening, as organizations confront present limitations before the technology matures enough to fulfill its promise. From our perspective, organizations can avoid the “trough of disillusionment” through an AI implementation strategy that incorporates the following:
- Building understanding and trust
- Designing human-guided systems for assistance
- Planning for modularity and iterative development
- Ensuring quality of data
Several recent advancements in enhancing semantic memory for AI systems (such as agent-queryable knowledge graphs and Graph-RAG) point to a future with independent reasoning, context retention, and knowledge integration. In the next stage of designing strategic scenarios, we will explore if we can leverage these emerging capabilities, to create agents proficient in more autonomous reasoning and contextually-grounded responses.
Opening the black box of large language models
While a comprehensive unboxing of the inner-workings of large language models (LLM) is out of the scope of this report, it is pertinent to outline some fundamentals, to enable a better understanding of the choices we have made in building our agentic models.
At their core, LLMs use a special kind of neural network called a transformer. Transformers are able to process and understand relationships between words in a sequence, allowing the model to handle complex language tasks. LLMs represent words as vectors (an array of numbers representing various features) that capture their meanings and relationships. This allows the model to understand that words like "cat" and "dog" are more similar to each other than to "car".
LLMs are essentially next-word predictors. During training, these models process billions of sentences and learn patterns—what words tend to follow what others, in what contexts. These patterns are stored as statistical relationships in their neural network weights (parameters that help the network decide which inputs are more important when making a prediction). An LLM learns by predicting the next word in a sentence, adjusting its weights each time it gets it wrong. Over time, it gets better at making accurate predictions and generating coherent text.
Please click on the “+” sign, to read the sub-chapters.
The memory of an agent refers to its context window or working memory. The context window is the maximum amount of information (measured in pieces of words or characters, i.e. tokens) that the LLM behind the agent can process at one time, when generating responses or understanding input. For instance, the context window of OpenAI’s GPT-4o LLM is 128,000 tokens (roughly 96000 words), whereas that of Google’s Gemini 2.0 Flash is 1,000,000 (roughly 750,000 words). A larger working memory allows the agent to remember and utilize more of our instructions, or more text from a document. Conversely, a smaller context window limits the amount of information the model can access; which can result in the model losing track of details, and producing less context-aware responses.
For truly autonomous agents, LLMs must possess more than just working memory. They must possess semantic memory that stores facts and concepts in a retrievable format; and associative learning capabilities that help them dynamically connect events to outcomes. Semantic memory and associative learning is essential for true autonomy because it enables agents to utilize structured knowledge about how an industry or the world operates.
Current LLMs, however, are limited in these aspects. LLMs do possess a form of semantic memory - the fixed weights and biases of their neural networks, which allow them to store and recall factual knowledge and concepts. However, this is not identical to human semantic memory that enables us to produce context-aware actions and responses. An LLM’s semantic networks are less interconnected and flexible than those of humans, resulting in poorer association and adaptability. LLMs’ associative learning capabilities are also primarily a function of the parameters fixed during training. This means their (reactive) actions are driven by the idea-connections they make based on patterns they have frequently observed in their training data, precluding creative or unconventional actions that may be required for autonomous functioning.
To close out this line of thought - imagine an airline employs a customer service agent. It offers a passenger an upgrade to business class for a discounted price, but the passenger ignores it. A day later, the agent can try to entice the passenger by sending a message that emphasizes the extra comfort and complimentary lounge access that come with a business class upgrade – only if explicitly prompted to do so. There is no automatic adaptation or evolving strategy based on past interactions; the agent/LLM simply responds to each prompt in isolation, without agency or persistent learning. In contrast, a true agent with semantic memory and associative learning could autonomously notice patterns—like a passenger ignoring upgrade offers—and proactively adjust its approach to better serve the passenger, without explicit prompting.
For straightforward tasks with limited scope, singular agents offer simplicity and cost-effectiveness. However, for complex tasks such as the identification of STEEP trends, we require a framework capable of handling larger contexts, parallel processing, and collaborative problem solving.
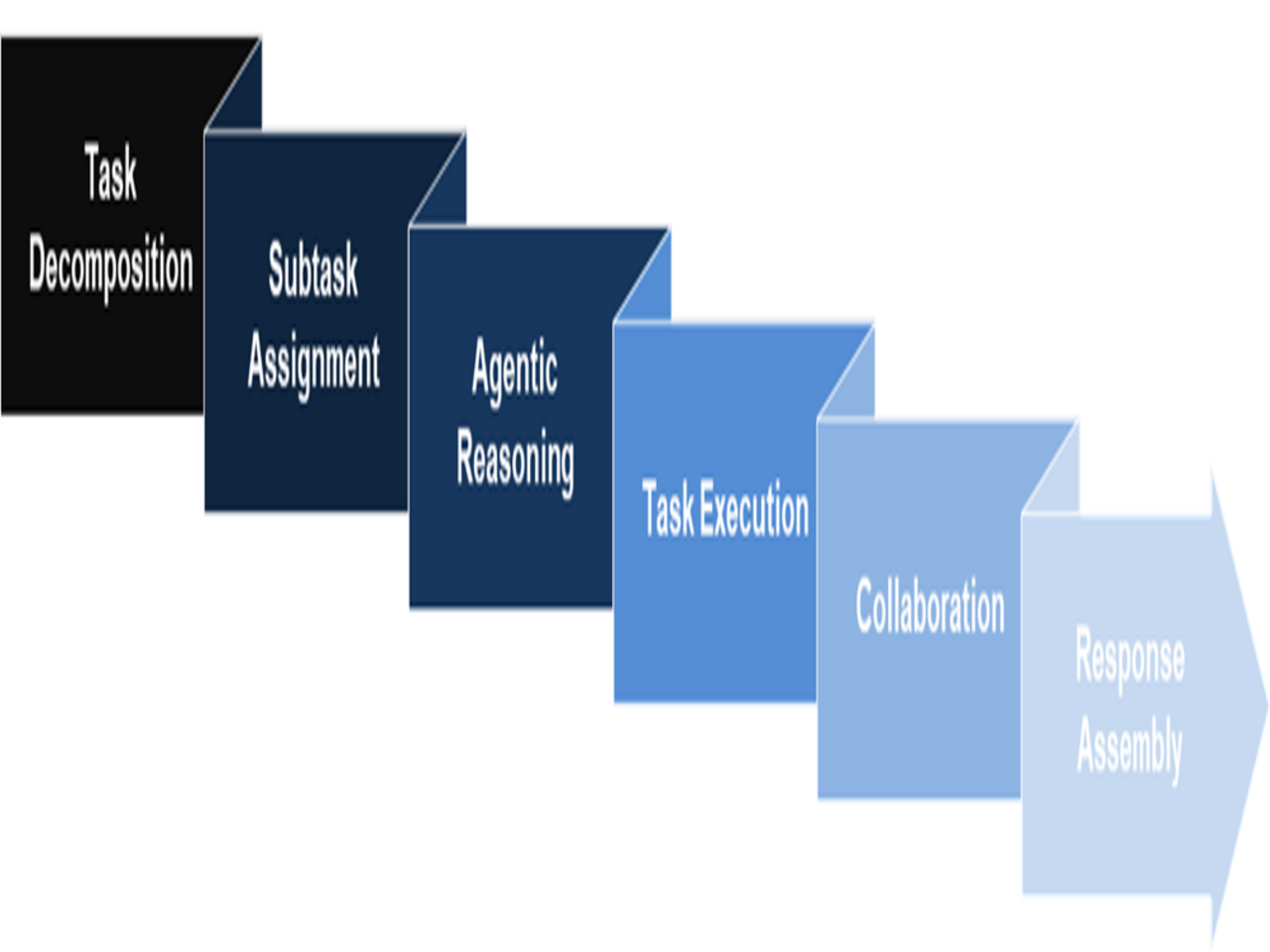
This is where multi-agent systems (MAS) come in. These systems distribute responsibilities across specialized agents that communicate and collaborate to achieve improved results. Theoretically, the workflow in these systems involves task decomposition, assignment of sub-tasks to agents, reasoning and execution of these tasks, communication of information as needed, and combination of results to deliver the response; all done autonomously.
Compared to singular agents, MAS offer several benefits that include fewer hallucinations as agents verify each others’ outputs; the ability to handle larger contexts as agents focus on sub-tasks within their context windows; efficient parallel processing as multiple agents may handle different tasks simultaneously; and more profound outputs through collaborative problem-solving that combines various agents’ outputs.
Current evidence suggests agents’ reliability varies significantly based on task complexity and agent design. In fact, the task duration (in terms of how long it takes humans to do it) beyond which the rate of successful completion starts to notably reduce, is currently a few minutes for some LLMs, while it is a few seconds for others. Moreover, the lack of a semantic cache precludes agents from independently understanding the quality of their outputs; or how to improve them.
To ensure consistent quality and reliability, for both trend-identification and uncertainty-impact scoring, we chose to build semi-autonomous multi-agent systems that combine agentic workflows with human oversight and guidance. This choice is grounded in our experience with attempting to build completely autonomous systems, which can be succinctly summed up as – “AI may succeed at a task that would challenge a human expert, but fail at something incredibly mundane”.
We provide more details of our systems below. In our experience, the advantages of these human-guided systems are that they result in more relevant responses, thanks to context and knowledge defined by experts; they result in more factual responses through the combination of agentic validation and human corroboration; they enable faster adaptability, through iterative manual modification of agents’ roles and addition or deletion of agents; and reduce the risk of systemic failure, thanks to the possibility of human verification of interim results.
Trend identification via human-guided systems
For our purpose, we use a human-guided multi-agent system that has four types of agents collaborating to identify and describe trends.

Prompts are natural language instructions that shape the tone, structure, and content of the agents’ output.
Since we have a human-guided system, our prompts are more intricate and explicit than what you may find in a seemingly autonomous one. Instead of having autonomous decomposition of the overall task and assignment of sub-tasks, we define and assign the sub-tasks for each set of agents. Task execution, collaboration and response assembly is what is left to the system.
Our prompts are designed to cause something akin to “chain-of-thought” reasoning from all agents. This means the prompts tell the agent to fulfill each sub-task through structured sequential steps; they encourage the agents to have reflection points for evaluation; and they promote agents justifying their choices (for example, the evidence gathering agents must justify why they think certain trends are referred to in a source).
We could have simply chosen to use models that offer this reasoning capability out-of-the-box. However, our approach gives us greater control and observability. This is achieved through the inclusion of “exit hatches” that tell agents how to stop being stuck in reactive loops (such as multiple abortive attempts to read a file), safeguards that prevent corrupted responses (such as restrictions on file access), and the reporting of step-by-step progress.
These prompts were iteratively refined through several rounds of prompt engineering, so as to reach the desired level of reliability and quality. These iterations also involved switching through different LLMs.
How does an agent know what a trend is? This is a question we resolved through instructional prompting with illustrative guidance – for each trend type, we provided instructions on what to look for, and illustrative examples of trends. For instance, here is a snippet from the prompt for identifying social trends:
Strictly only look for emerging behaviors, actions, preferences, values, and expectations among travelers.
Examples of these trends include
- Conscious tourism: Travelers seeking to minimize negative impacts and maximize positive contributions to destinations they visit
- Generational shift: Changing travel preferences and behaviors as younger generations (Millennials, Gen Z, Gen Alpha) become dominant consumer groups
- Personalized experiences: Increased demand from travelers for tailored itineraries and services based on individual preferences.
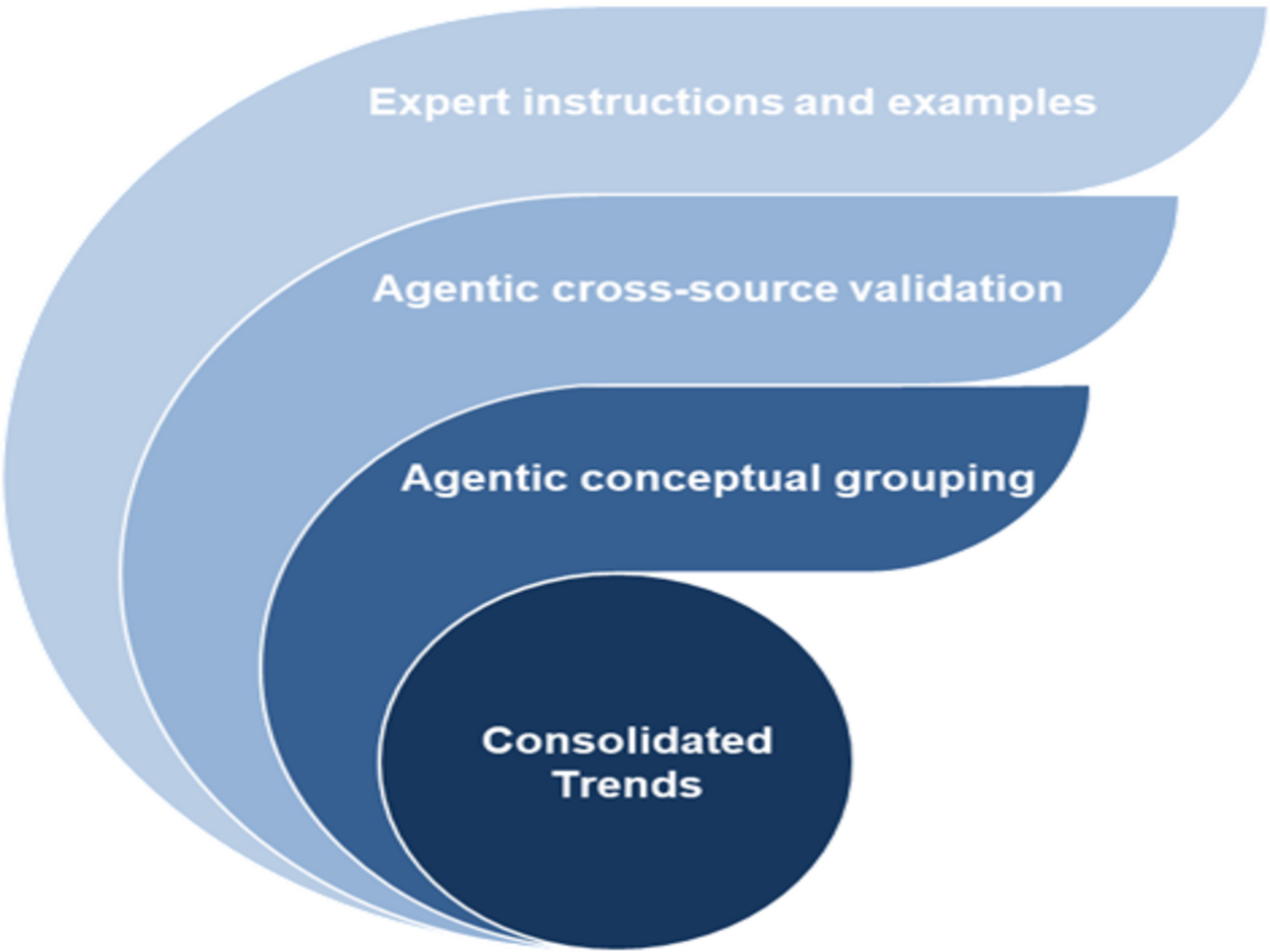
As stated above, a set of synthesis agents combine trends listed in the interim result, to output the final set of trend names and descriptions. These agents autonomously (meaning without us prompting it to) do this based on:
- Cross-source validation: when multiple sources reported similar findings, agents consolidate them to create more robust, multi-sourced trends.
- Conceptual grouping: if the agents identify conceptual similarities between the descriptions of trends that have different names, it combines them. For instance, the present trend of “Generational Travel Evolution” combines trends such as “Generational shift in travel preferences”, “Gen Z Travel Preferences”, and “Generational Shift in Travel” found in the interim result.
The survey we conducted to obtain trends that our agents could not identify, and to have experts score the trends on uncertainty and impact, received 47 completed responses. Respondents had designations such as CEO, Director of Strategy, Partner, Head of Engineering, Venture Manager etc. Going by the email domains, ninety eight percent of our respondents were from Europe, with the other 2% coming from North America.
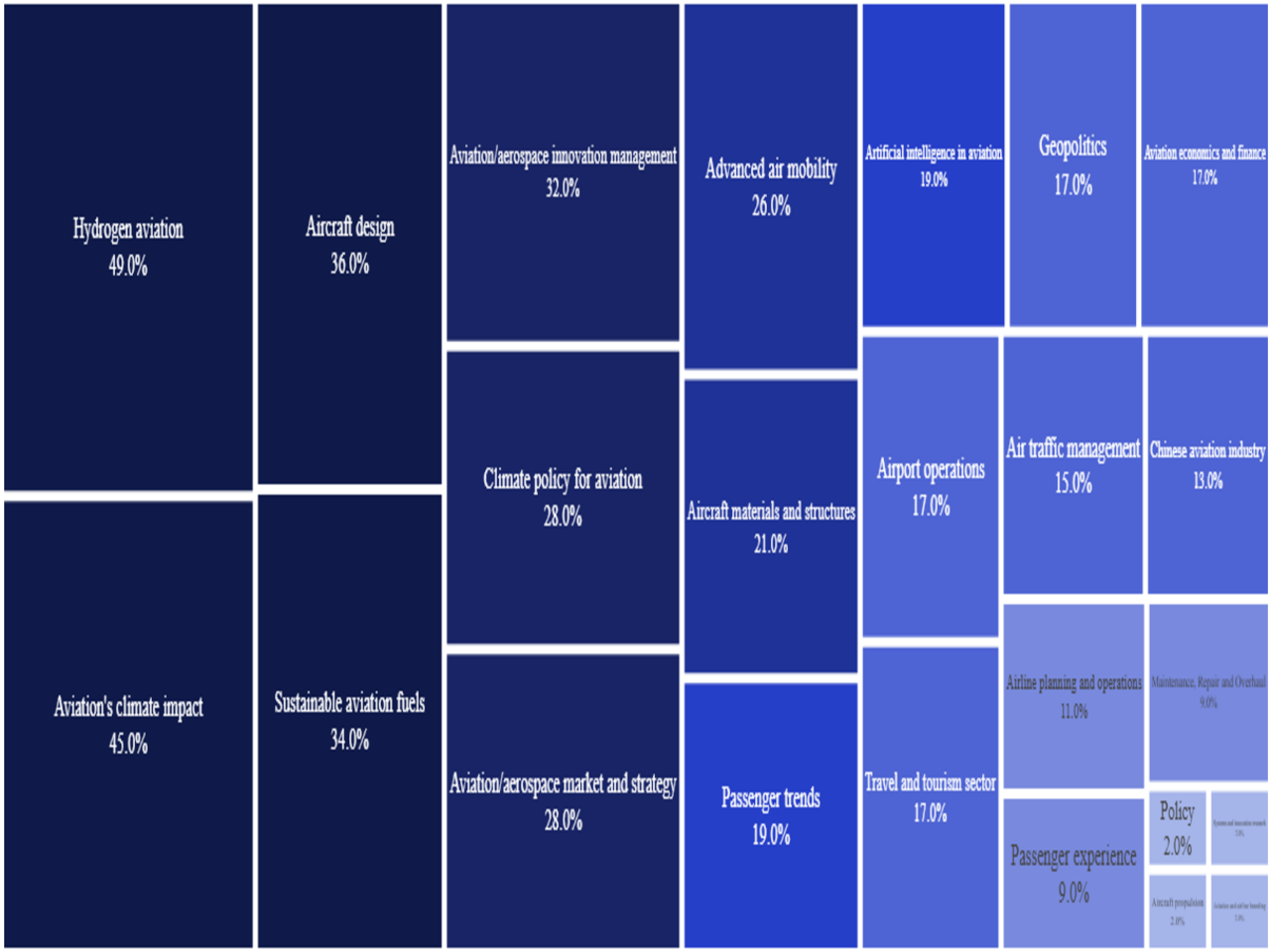
Multiple areas of expertise were represented in the survey; with Hydrogen aviation, Aviation’s climate impact, Aircraft design, Sustainable aviation fuels and Aviation/Aerospace innovation management being the top-five areas. Airline planning and operations, Passenger experience, MRO, Aviation and airline branding, and Systems and innovation research were the least represented areas.
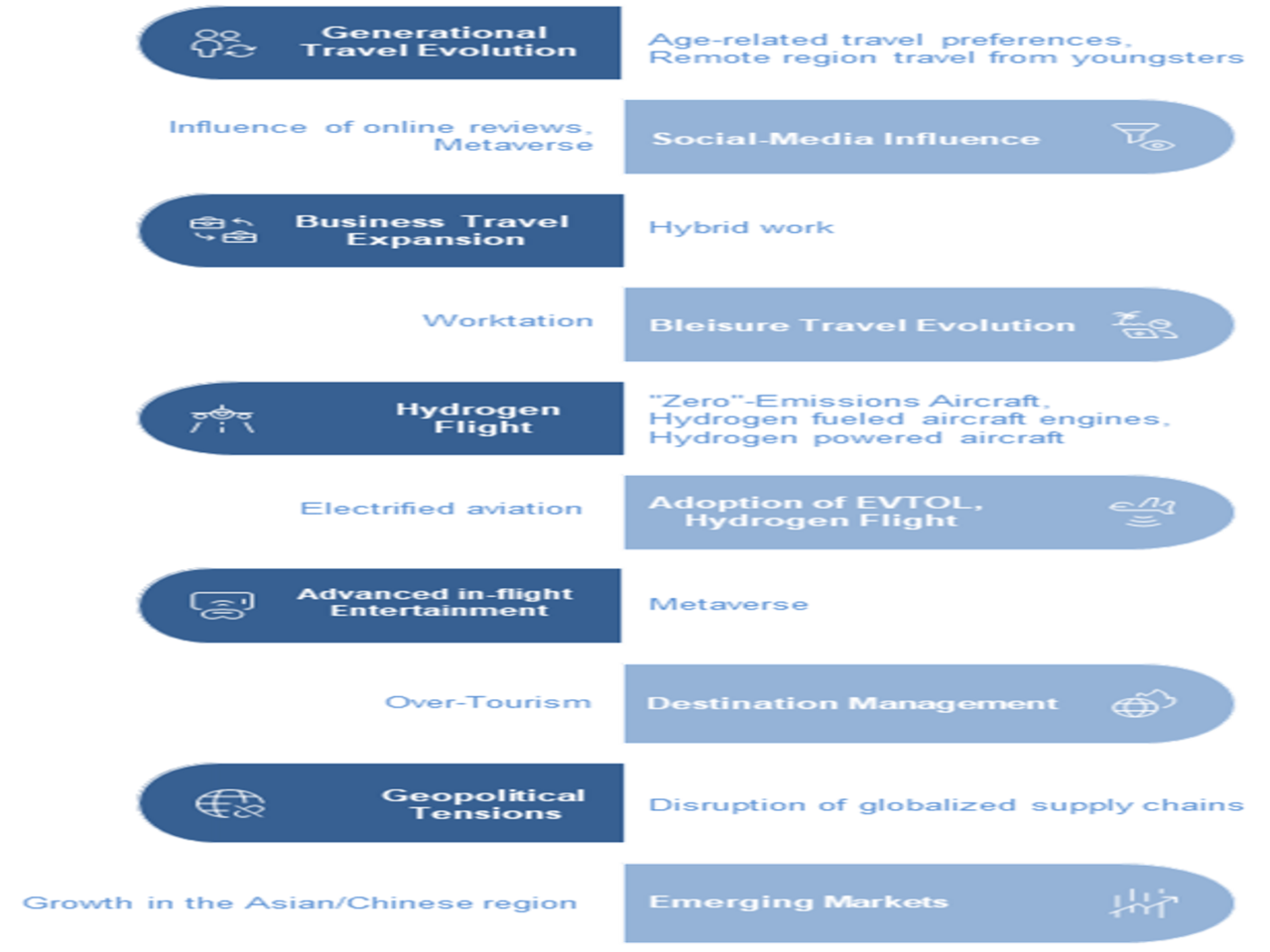
Among the trend suggestions we received, all but two were connected to existing identified trends. This indicates the agents have been able to considerably cover the relevant trendspace. The two trends we did add to the list were “Expansion of High-speed Rail” and “Regulation of non-CO2 effects”. In total, we had 25 trends after the survey.
Existing trends are in the balloons.
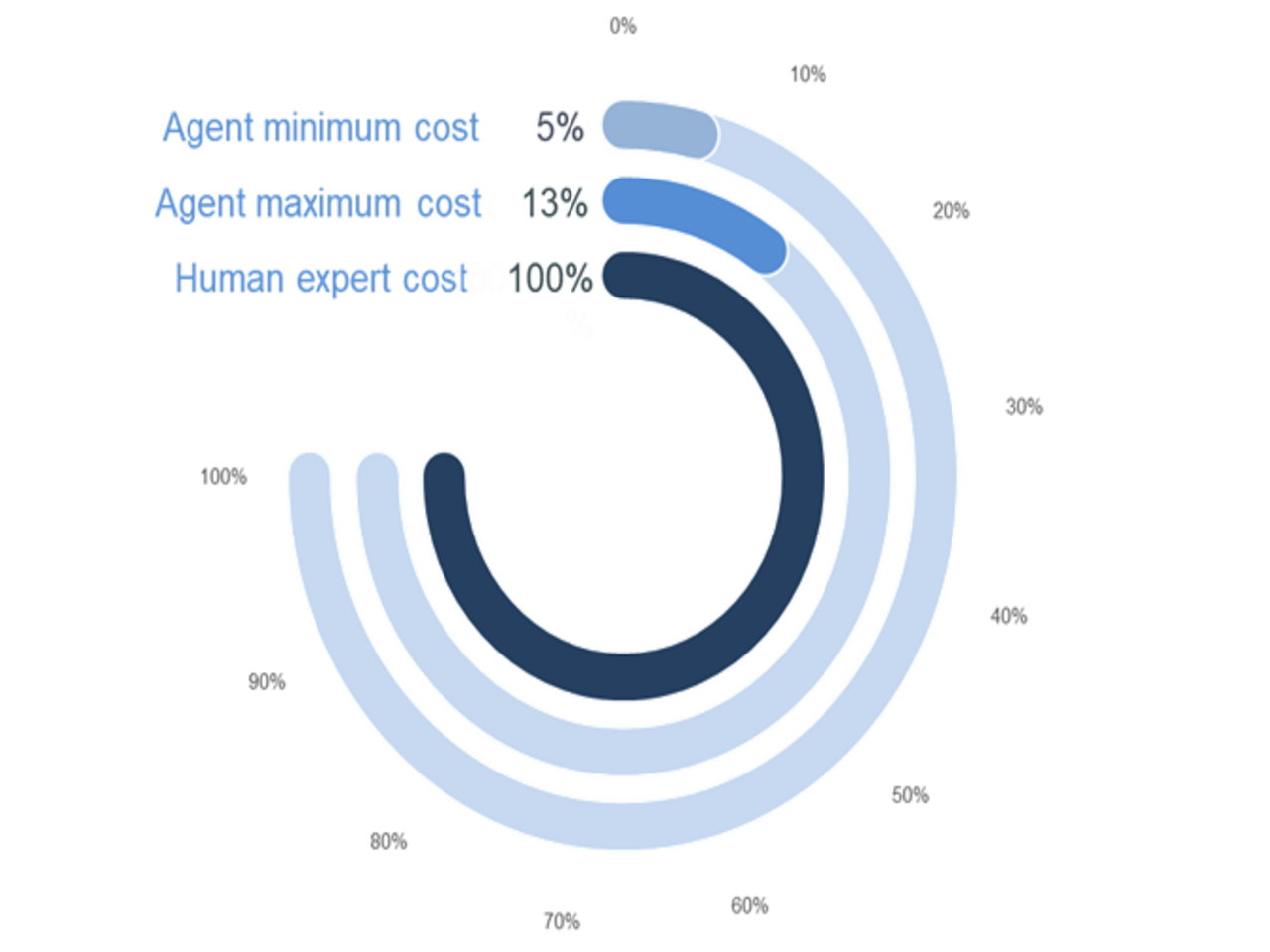
What is also notable are the time and cost-efficiencies we experienced when we switched to using agents to discover trends. A process that would previously takes weeks is now accomplished in minutes. On the cost side, we found that for one successful trend-identification run, the cost would be between 5% and 13% of the hourly costs of a human expert doing the same task, depending on the STEEP trend type.
This estimate does come with some caveats – 1) The costs refer to the LLM processing costs (i.e., the tokens spent through the API); they do not include the “CAPEX” spent on developing the multi-agent system 2) While this is representative of one successful run, the eventual set of trends were obtained via multiple successful runs 3) The costs were possibly moderated because we used a workflow that was significantly manually structured (versus using one based on models with in-built reasoning capabilities).
Trend scoring via human-guided systems
To score the trends on uncertainty and impact, we once again iteratively developed human-guided MAS.

How the scoring for impact happens is – source and evidence agents combine to identify possible impacts the evolution of a trend may have on aviation’s stakeholders and aspects such as flight operations, aircraft design etc.; scenario agents create hypothetical scenarios that describe how aviation has changed if the trend has strongly developed, whenever that is; a first set of scoring agents score the trend by reading multiple such scenarios; a second set of scoring agents then provide a final score after comparing the impacts of this trend with those of other trends.
The scoring for uncertainty is eminently similar; the only difference being that scoring is done on the basis of summaries created by a set of summary agents. These summaries describe events, factors, phenomenon that either challenge or support continual positive evolution of the trend till 2035. In both cases, the final score for each trend is the average of the scores from the second set of scoring agents.
The trend-scoring exercise demonstrated the semantic-associative memory limitations of LLMs.
For instance, in the first round of scoring, the impact agents were instructed to assign impact scores in proportion to the number of affected aspects or stakeholders and the severity of the disruption caused by the trend. The results showed that the agents could not differentiate levels of disruption. For example, the average impact score for the trend of “Geopolitical Tensions” was an 8.5, while the agents scored “Advanced In-flight Entertainment” a 9.0. This counter-intuitive scoring seems to be the result of the LLM merely responding more to the narrative structure and emotional valence in the scenario descriptions. With an AI-assisted analysis, we discovered that both the impact and uncertainty agents tend to score trends higher when the scenarios or summaries have extreme language - text containing hyperbolic words like "revolutionary," "groundbreaking," "urgent threat," "crisis".
In summary, the agents and the LLMs behind them are not able to independently differentiate a fundamentally transformative/uncertain phenomenon from one that is relatively incremental/certain. Rather, they apparently recognize and reproduce textual patterns they have seen during training. In other words, when an LLM sees extreme language, it most likely associates the text with high impact or uncertainty, based on previous examples it has been trained on.
In an ideal world, we would move the system from textual pattern-matching to actual understanding by providing multiple explicit knowledge graphs that make clear causal relationships between concepts, feedback loops, and criticality of concepts and relationships. Considering, however, time and resource constraints, we made the practical choice of achieving contextual grounding via comparative scoring aided by human guidance.
After the first round of scoring for uncertainty and impact, we got in touch with some of our survey respondents, to understand how they scored the trends. Following discovering that several of them scored in a two-step process wherein they first consider the impact or uncertainty of an individual trend and then compare it to those of other trends to reach a final score, we decided to make the agents do the same.
A new intermediate set of agents were made to compare the impacts or uncertainty-factors of each trend with those of the trend with the highest impact (hydrogen flight) or uncertainty (geopolitical tensions). To aid this comparison, a scenario of possible impacts of hydrogen flight and a summary of uncertainties of geopolitical tensions was provided to the agents by us. The content used text generated by the above-mentioned scenario and the summary agents. In both cases, extreme language was preserved. Based on this comparison, the scores for impact and uncertainty were adjusted.

On the basis of these intermediate scores, we took the two trends with the highest and lowest average scores from each of the STEEP types, and classified them as “Low”, “Average”, “Above average”, or “High” impact or uncertainty trends. Next, we created exemplary scenarios and summaries for these trends, based on existing ones. We modified the text in these to correspond to the label of the trend; use of hyperbolic language ranged between highest for trends with a “High” label, and lowest for those with a “Low” label.
In the final round of scoring, agents were made to compare the impacts or uncertainty-factors of each trend with those of these labelled trends. These agents were instructed that these classified scenarios and summaries describe impacts and uncertainties that are representative of the particular class; and that they should factor this in, when they decide on a new score. The response included a new score, a classification label, and a justification for why this new score was given.
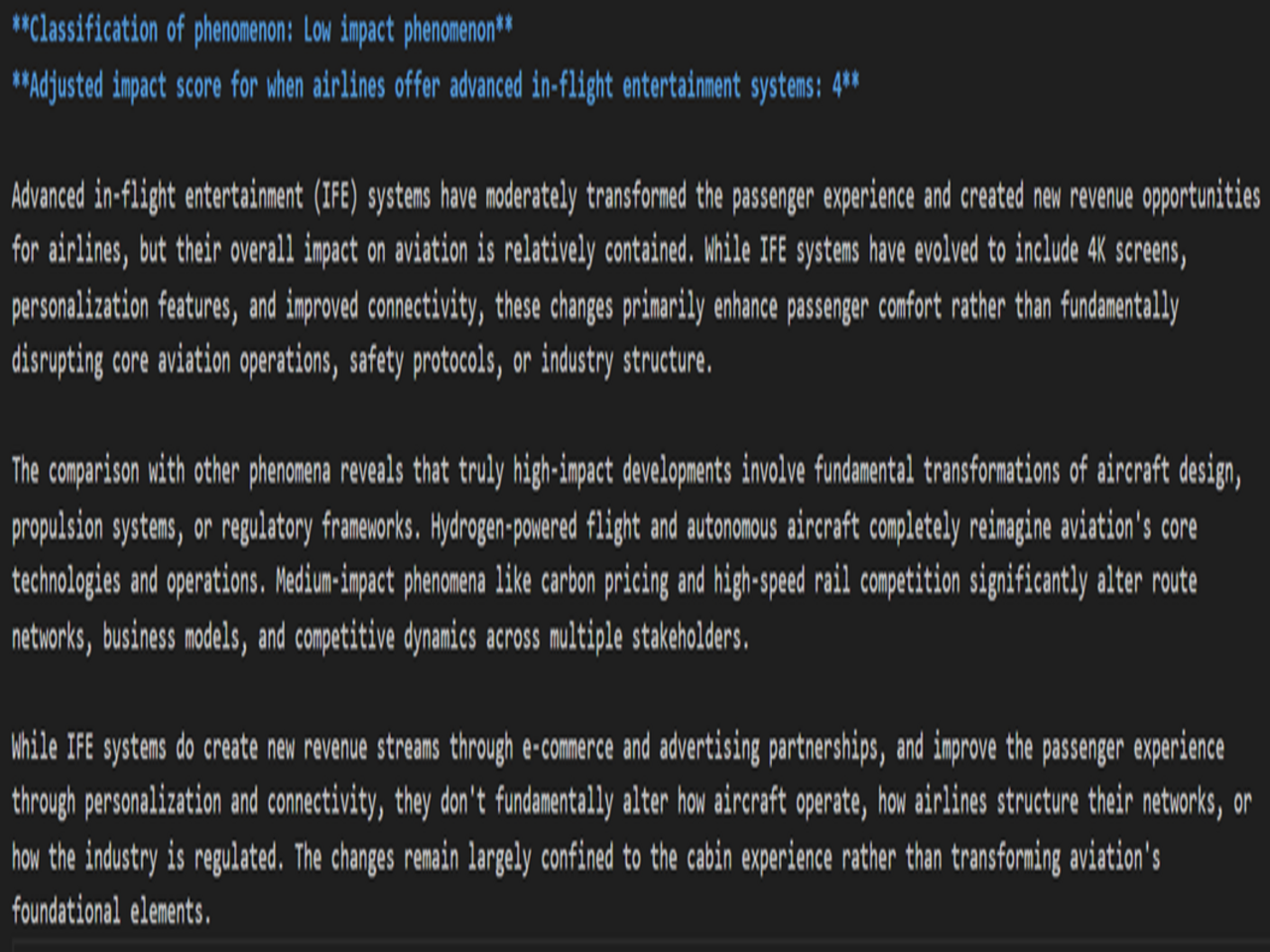
For instance, the trend of advanced in-flight entertainment was now given an average score of 4.4. As an example, the score of one of the agents was based on the justification that
“Advanced in-flight entertainment (IFE) systems have moderately transformed the passenger experience and created new revenue opportunities for airlines, but their overall impact on aviation is relatively contained. While IFE systems have evolved to include 4K screens, personalization features, and improved connectivity, these changes primarily enhance passenger comfort rather than fundamentally disrupting core aviation operations, safety protocols, or industry structure."
On the side of uncertainty, for instance, the trend of hydrogen flight was given an average uncertainty score of 7.5. The score of one of the agents was based on the justification that
“Achieving hydrogen-powered flight by 2035 faces significant uncertainties across multiple dimensions that justify its high uncertainty classification. The technical challenges are substantial…Infrastructure development requires an entirely new ecosystem for hydrogen production…Economic barriers are evident from Universal Hydrogen's liquidation despite technical success…Regulatory frameworks and certification processes for hydrogen aviation remain underdeveloped…While hydrogen flight shows some positive developments…these are outweighed by major obstacles, particularly Airbus's postponement of its ZEROe project from 2035 to the 2040s."

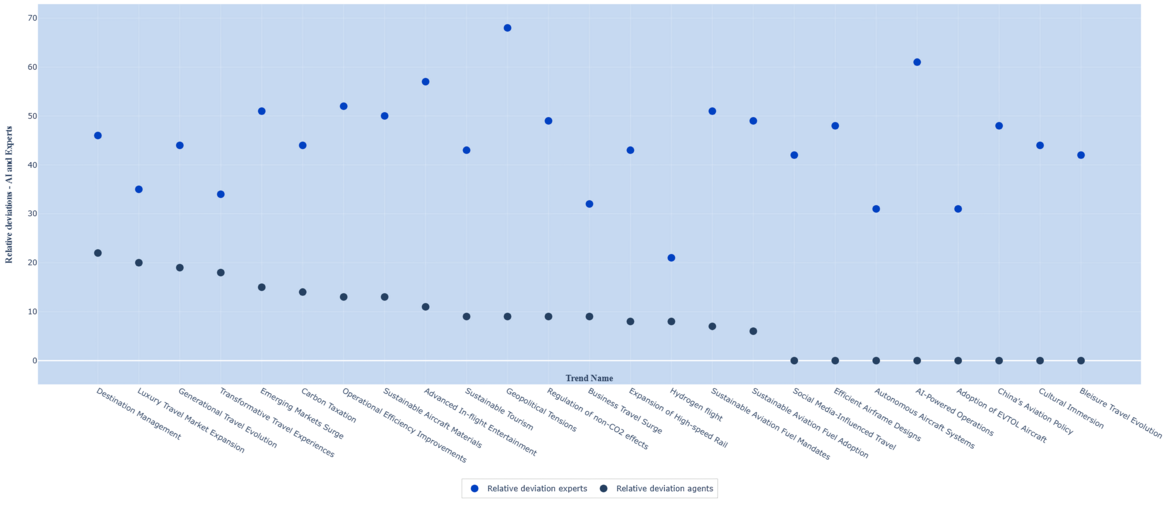
Looking at the results of impact scoring by the experts and agents, we see a moderate correlation between the two sets of scores (R-Squared of 47%).


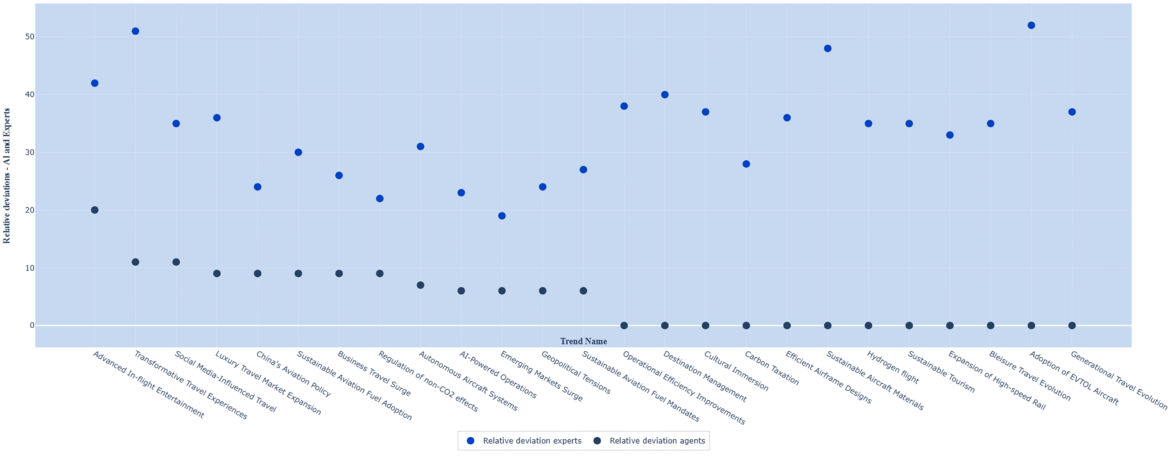
In general, the mean scores of the agents is higher than those of the experts, with an average absolute deviation of 19%. The absolute deviation is highest for the trend of “Adoption of EVTOL aircraft”, where the agents’ average score is 57% higher than those of the experts; the lowest deviation is for the trend of “Carbon taxation”, at 0.3%. In the majority of cases, the deviation between the agents’ and experts scores is lower than the relative deviation for the expert scores.

The average deviation is highest for Technological and Environmental trends, both at 24%. Interestingly, these trend-types also have close to the highest levels of average relative deviation in the expert scores, at 37%. There is moderate correlation (57%) between the agent-expert deviation and the relative deviation among the experts.


Looking at the results of uncertainty scoring by the experts and agents, we once again see a moderate correlation between the two sets of scores (R-Squared of 47%).


Just like in the case of the impact scores, the mean scores of the agents is higher than those of the experts, with an average absolute deviation of 23%. The absolute deviation is highest for the trend of “Sustainable Aviation Fuel Adoption”, where the agents’ average score is 52% higher than those of the experts; the lowest deviation is for the trend of “Autonomous Aircraft Systems”, at 2%. For each trend, the deviation between the agents’ and experts scores is lower than the relative deviation for the expert scores.

The average deviation is highest for Political trends, at 29%. This trend-type also has the highest levels of relative deviation among the expert scores, at 51%. There is moderate correlation (56%) between the agent-expert deviation and the relative deviation among the experts.


To obtain the final uncertainty-impact score distribution, we took the average of all expert and agent scores for each trend. Uncertainty scores lie within the range of three to nine; 75% of the scores are under a score of around five. Impact scores lie between the range of four to nine; 75% of the scores are under a score of around seven.
On average, political trends scored the highest on impact (average of 6.9), while social trends scored the lowest (average of 5.8). On the side of uncertainty, technology trends scored the highest (average of 5.5), while economic trends scored the lowest (average of 4.7).
In the case of both uncertainty and impact, we found that the relative deviation among agents' scores was always lower than among expert scores. In other words, agents agreed with each other more than human experts did, when scoring the trends. For some trends, in fact, all agents gave the same score.
Concluding thoughts and next steps
AI agents are very much on the way to reach the peak of the Gartner Hype Cycle in 2025. There is intense publicity and high expectations. Real-world deployments, however, are still limited; and the technology often does not deliver on all that is expected of it.
While we have waxed eloquent on the limitations of LLMs, which preclude truly autonomous agents, we must emphasize that these are shortcomings very much in the present. Several recent advancements in enhancing semantic memory for AI systems point to a future with independent reasoning, context retention, and knowledge integration. For instance, the emergence of frameworks that can be used to build agent-queryable knowledge graphs, and that of Graph-RAG, which enables agents to use graphs as sources of structured, context-rich data, can result in enhanced autonomous reasoning and more accurate and relevant responses. In the meantime, as we have shown with the trend scoring, there are practical methods to contextually ground agents’ reasoning through human guidance.
For now, most agents function more as advanced assistants than true autonomous operators, just like in the agentic systems we have built. While these require periodic human intervention, and much more explicit prompting and relatively elongated development-timelines, the benefits once built, in terms of time and cost-efficiencies, and of accuracy and relevancy of responses, are undeniable. Especially in certain applications such as trend identification, the combination of humans and assistive agents offer significant advantages - and this is not an isolated case.

The goal of this report was to elucidate that it is possible to productively apply generative AI, even with its present limitations. Based on our own experience, organizations can avoid the “trough of disillusionment” through an AI implementation strategy that incorporates the following:
Acquiring stakeholder trust
LLMs and AI agents do face skepticism from management and clients. Often this is the outcome of LLMs still being black boxes, the capabilities and limitations of which are not very well understood.
A stakeholder mapping can help you identify the decision-makers and proponents of GenAI in your of your organization.
- The implementation of the AI solutions begins with jointly defining with these key-persons, the goals of the organization, what makes up success and KPIs to measure success.
- This is followed by the formulation of an AI governance framework that prescribes roles and responsibilities, and principles such as human-in-the-loop and data-protection.
- In a discovery-phase, work with decision-makers and fellow-colleagues to identify “low-risk, high-impact” use-cases that will provide fast, visible benefits.
- Report transparently, the achieved benefits but also, risks (such as rate of hallucination) and limitations.
Designing systems with human-guidance
The EU AI Act obligates providers and deployers of AI systems to design these systems so "natural persons" can oversee, control, or intervene during operation. Humans, and not AI, should be accountable for the eventual outputs of these systems.
Note that the bottleneck in such systems is the human-in-loop. Rapid AI generation loses value when humans cannot validate the results quickly enough, creating a chokepoint where large volumes of responses must be checked for errors. The solution here lies in ensuring that workflows and outputs remain manageable and explainable enough for thorough human verification. Inability to interpret AI decisions may lead to violations of the EU AI act.
Planning for iterative development towards greater complexity
Understand that current AI agents are most appropriate for applications involving well-defined, predictable environments, rather than open-ended ones. It is best to create workflows where AI handles high-volume repetitive tasks.
Deployment of agent-based systems must start with applications of limited-scope; automation of tasks with manual bottlenecks (such as summarizing multiple documents) is presently where you can get the highest ROI. As greater trust and experience is built-up through these “easy wins”, organizations should be more confident about employing GenAI for more complex tasks (such as customer service).
Organizations must plan for ongoing costs for iterating through, as new goals and success criteria may emerge, or new more powerful models and tools may be available
Integrate with quality data
AI systems' inability to adapt, and learn over time creates a fundamental barrier to enterprise value creation. For more adaptive agents, link the agents to the most relevant, up-to-date data. Even better if the agents are given access to knowledge-graphs that explain relationships between different variables and concepts.
The next report of Trend Monitor 2025 will describe future scenarios where aviation has been impacted to varying degrees by certain critical trends. These scenarios will be described through a combination of agent-led development and expert-validation.
We aim to detail the aspects such as implications for the diverse stakeholders in these futures. On the methodological side, we will explore if we can create agents that learn from knowledge graphs, and thus, are capable of more autonomous reasoning and contextually-grounded responses.