While a detailed unboxing of the inner-workings of large language models (LLM) is out of our scope, it is pertinent to outline some fundamentals, to enable a better understanding of the choices we have made in building our agentic models.
At their core, LLMs use a special kind of neural network called a transformer. Transformers are able to process and understand relationships between words in a sequence, allowing the model to handle complex language tasks much better than older models. LLMs represent words as vectors (lists of numbers representing various features) that capture their meanings and relationships. This allows the model to understand that words like "cat" and "dog" are more similar to each other than to "car".
LLMs are essentially next-word predictors. During training, these models process billions of sentences and learns patterns—what words tend to follow what others, in what contexts. These patterns are stored as statistical relationships in their neural network weights (parameters that help the network decide which inputs are more important when making a prediction). An LLM learns by predicting the next word in a sentence, adjusting its weights each time it gets it wrong. Over time, it gets better at making accurate predictions and generating coherent text
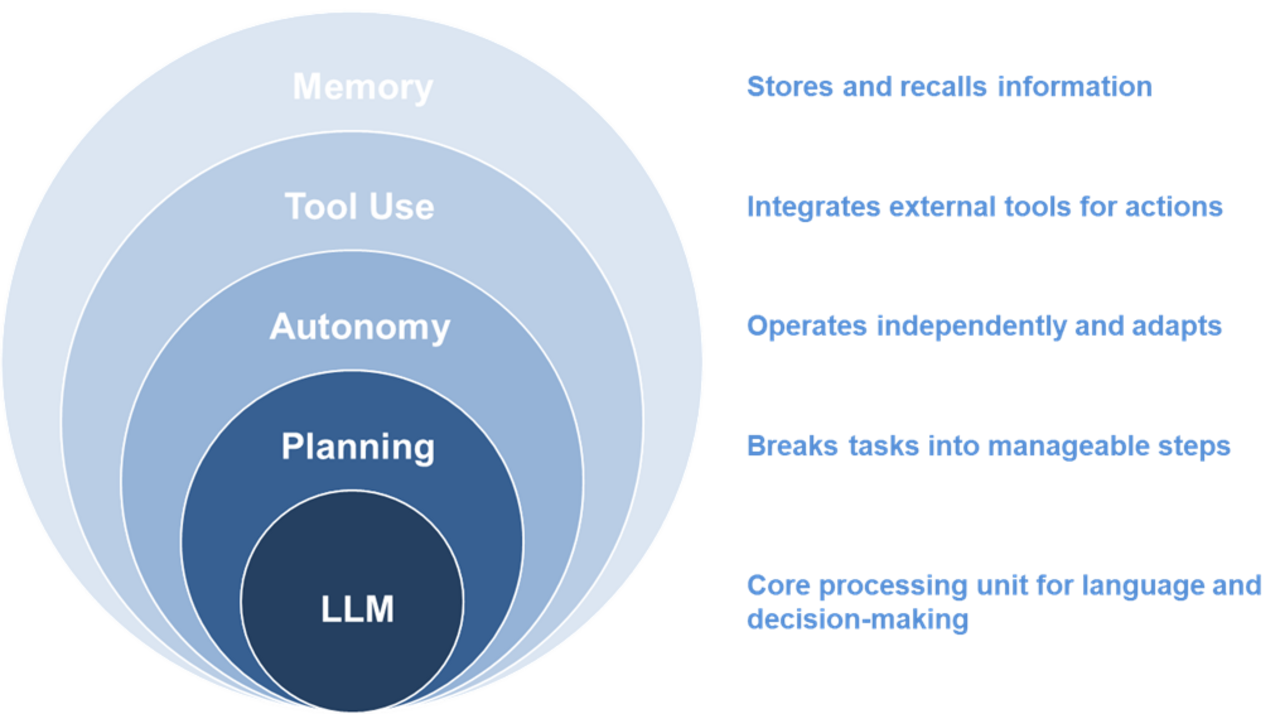
An AI agent is a specialized instance of a LLM created to perform a very specific task. In theory, these agents are capable of autonomous planning, adapting to issues and errors, keeping various forms of data in memory, and interacting with other agents and tools (such as web search and APIs).
The "agentic future" refers to a vision of AI agents that are not just passive tools responding to prompts, but completely autonomous entities that can set their own goals, make decisions about when and how to act; and learn from experience in a meaningful, transferable way. With the current memory-architecture of LLMs, this future may be somewhat distant.
The memory of an agent refers to its context window or working memory. The context window is the maximum amount of information (measured in pieces of words or characters, i.e. tokens) that the LLM behind the agent can process at one time, when generating responses or understanding input. For instance, the context window of OpenAI’s GPT-4o LLM is 128,000 tokens (roughly 96000 words), whereas that of Google’s Gemini 2.0 Flash is 1,000,000 (roughly 750,000 words). A larger working memory allows the agent to remember and utilize more of our instructions or a document. Conversely, a smaller context window limits the amount of information the model can access, which can result in the model losing track of details and producing less context-aware responses.
For truly autonomous agents, LLMs must provide more than just working memory. They must equip agents with semantic memory that organizes facts, concepts, and relationships in a retrievable format. Semantic memory is essential for true autonomy because it enables agents to utilize structured knowledge about an industry or the world, which is critical for relevant, context-aware actions and responses. Current agents by themselves, however, do not possess true semantic memory. While their base models have access to vast amounts of factual knowledge, this knowledge exists as encoded statistical associations learned during training; meaning there are no explicit structures for organizing and updating semantic concepts. This means that agents produce responses based on predictions aligned with patterns in LLM training data, and not based on any the deep semantic understanding.
For straightforward tasks with limited scope, singular agents offer simplicity and cost-effectiveness. However, for complex assignments such as the identification of influential STEEP trends, we require a framework capable of handling larger contexts, specialization, parallel processing and collaborative problem solving.
This is where multi-agent systems come in. Unlike single-agent approaches, these systems distribute responsibilities across specialized entities that communicate and collaborate to achieve better results. Theoretically, the workflow in these systems involves task decomposition, assignment of sub-tasks, reasoning and execution of these tasks, and combining results and delivering the response; all done autonomously.
These four scenarios will then be described through a combination of AI agent-led scenario development and expert-validation. To describe the scenarios, some of the other critical trends may be used, in a manner that the scenarios are consistent and plausible. Eventually, agents are used to recommend how stakeholders should strategize, prioritize and prepare for these scenarios.