
While a detailed unboxing of the inner-workings of large language models (LLM) is out of our scope, it is pertinent to outline some fundamentals, to enable a better understanding of the choices we have made in building our agentic models.
At their core, LLMs use a special kind of neural network called a transformer. Transformers are able to process and understand relationships between words in a sequence, allowing the model to handle complex language tasks much better than older models. LLMs represent words as vectors (lists of numbers representing various features) that capture their meanings and relationships. This allows the model to understand that words like "cat" and "dog" are more similar to each other than to "car".
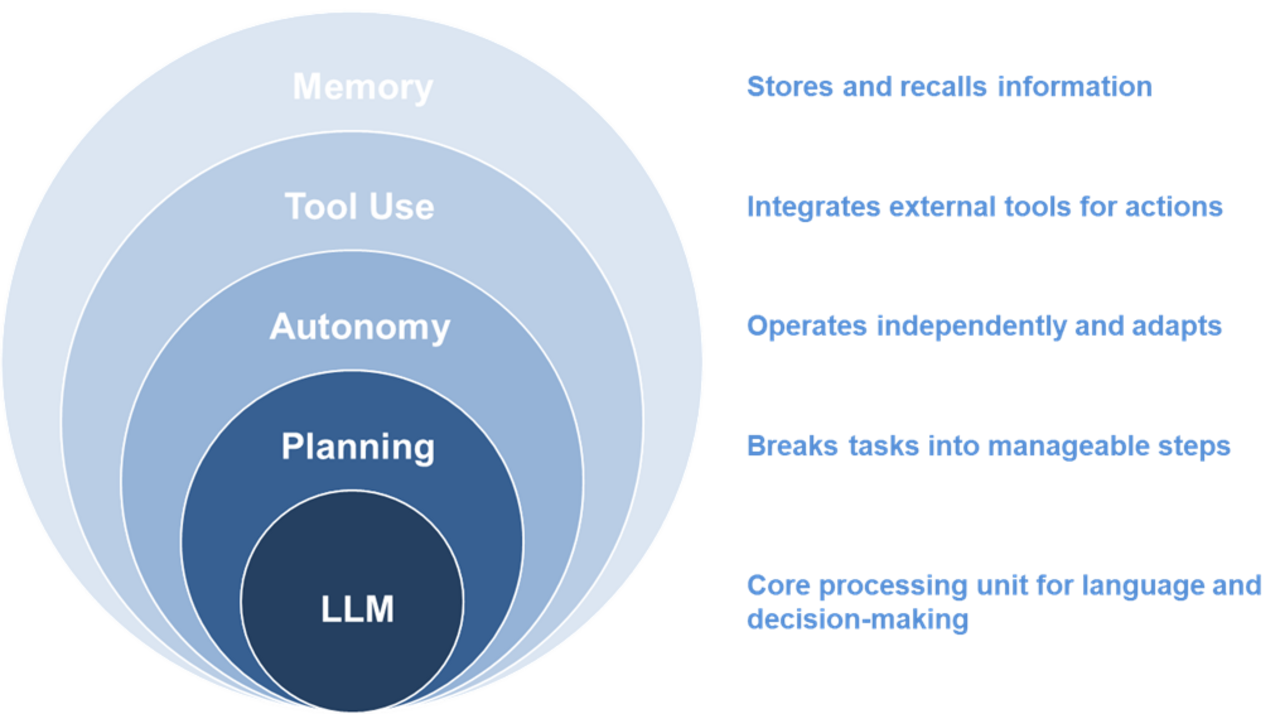
LLM-based agent architecture
LLMs are essentially next-word predictors. During training, these models process billions of sentences and learns patterns—what words tend to follow what others, in what contexts. These patterns are stored as statistical relationships in their neural network weights (parameters that help the network decide which inputs are more important when making a prediction). An LLM learns by predicting the next word in a sentence, adjusting its weights each time it gets it wrong. Over time, it gets better at making accurate predictions and generating coherent text
An AI agent is a specialized instance of a LLM created to perform a very specific task. In theory, these agents are capable of autonomous planning, adapting to issues and errors, keeping various forms of data in memory, and interacting with other agents and tools (such as web search and APIs).
How close are we to the agentic future?
The "agentic future" refers to a vision of AI agents that are not just passive tools responding to prompts, but completely autonomous entities that can set their own goals, make decisions about when and how to act; and learn from experience in a meaningful, transferable way. With the current memory-architecture of LLMs, this future may be somewhat distant.
The memory of an agent refers to its context window or working memory
The context window is the maximum amount of information (measured in pieces of words or characters, i.e. tokens) that the LLM behind the agent can process at one time, when generating responses or understanding input. For instance, the context window of OpenAI’s GPT-4o LLM is 128,000 tokens (roughly 96000 words), whereas that of Google’s Gemini 2.0 Flash is 1,000,000 (roughly 750,000 words). A larger working memory allows the agent to remember and utilize more of our instructions or a document. Conversely, a smaller context window limits the amount of information the model can access, which can result in the model losing track of details and producing less context-aware responses.
Semantic memory is essential for true autonomy
For truly autonomous agents, LLMs must provide more than just working memory. They must equip agents with semantic memory that organizes facts, concepts, and relationships in a retrievable format. Semantic memory is essential for true autonomy because it enables agents to utilize structured knowledge about an industry or the world, which is critical for relevant, context-aware actions and responses. Current agents by themselves, however, do not possess true semantic memory. While their base models have access to vast amounts of factual knowledge, this knowledge exists as encoded statistical associations learned during training; meaning there are no explicit structures for organizing and updating semantic concepts. This means that agents produce responses based on predictions aligned with patterns in LLM training data, and not based on any the deep semantic understanding.
Trend identification via multi-agent systems
For straightforward tasks with limited scope, singular agents offer simplicity and cost-effectiveness. However, for complex assignments such as the identification of influential STEEP trends, we require a framework capable of handling larger contexts, specialization, parallel processing and collaborative problem solving.
This is where multi-agent systems come in. Unlike single-agent approaches, these systems distribute responsibilities across specialized entities that communicate and collaborate to achieve better results. Theoretically, the workflow in these systems involves task decomposition, assignment of sub-tasks, reasoning and execution of these tasks, and combining results and delivering the response; all done autonomously.
Compared to singular agents, multi-agent systems offer several benefits that include fewer hallucinations, the ability to handle larger contexts, efficient parallel processing, and more profound outputs through collaborative problem-solving.
Theoretical multi-agent system workflow
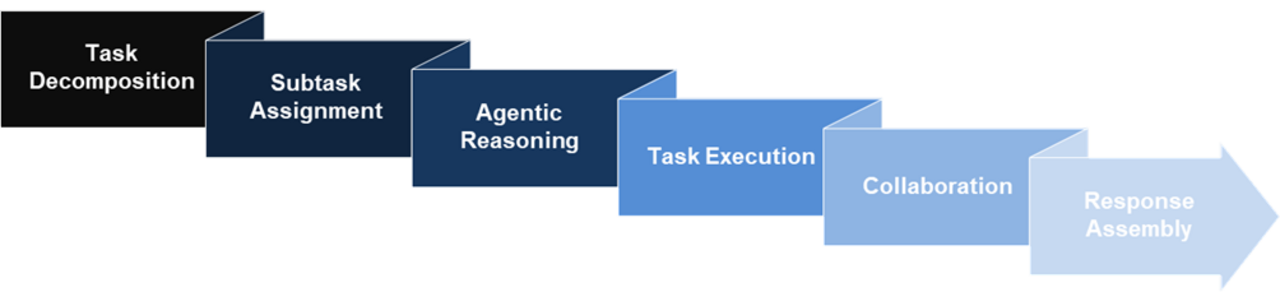
Enhanced problem-solving via multi-agent systems
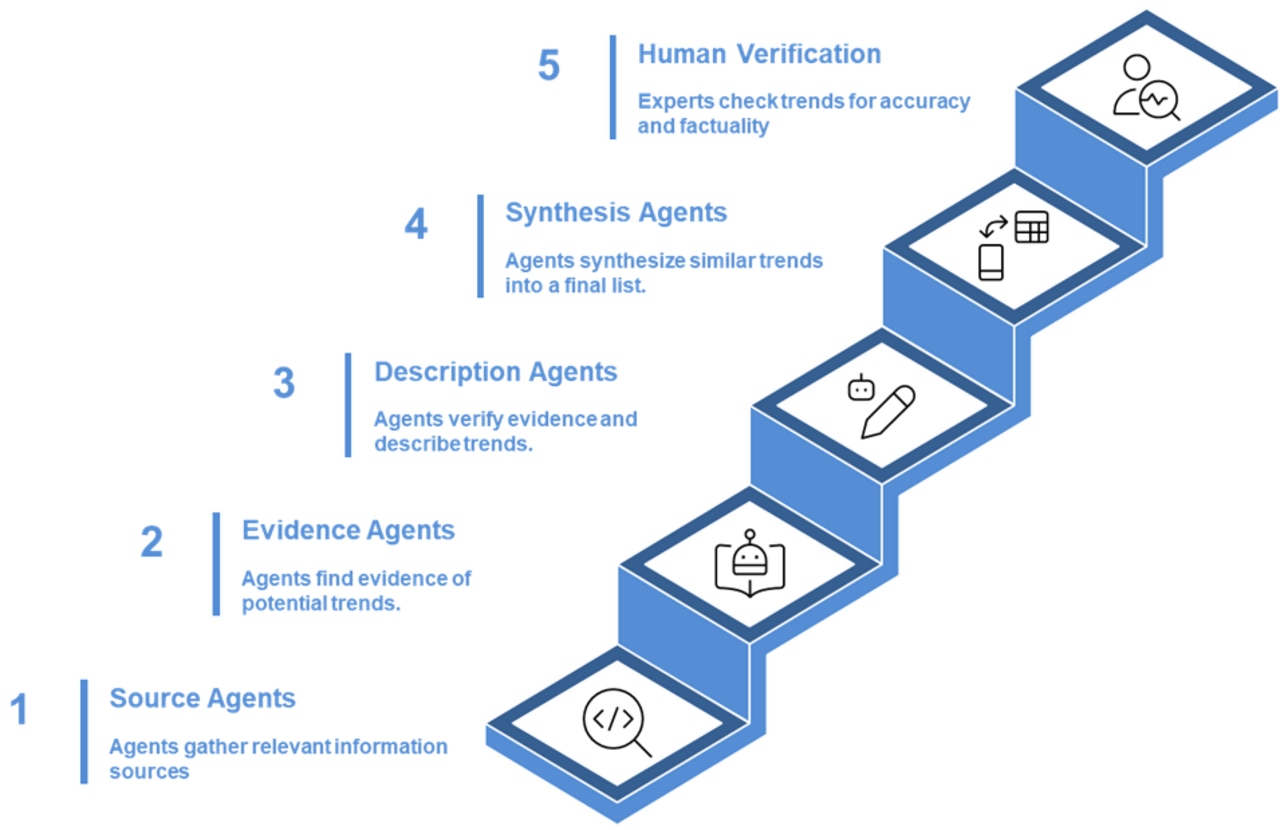
A semi-autonomous system to identify trends
Exemplary respose of the trend identification system

Quality and reliability through semi-autonomy
While current multi-agent frameworks promise full autonomy, in our experience (as well of others), these systems still require significant human oversight. Owing to the lack of robust semantic memory, and due to other reasons, current evidence suggests agents demonstrate inconsistent success rates in task completion; with reliability varying significantly based on task complexity and agent design. Errors by one agent can quickly cascade into a system-wide failure. The results of our early experiments in attempting to build autonomous systems align with this evidence.
Manual input: tasks and prompts
To ensure consistent quality and reliability, we chose to build a semi-autonomous system. Instead of having autonomous decomposition of the overall task and the assignment of sub-tasks, we defined the sub-tasks for each set of agents manually; and instead of having autonomous reasoning by the agents, we provided detailed prompts on how to fulfill these tasks.
Our prompts are much more intricate and explicit than what you may find in a seemingly autonomous system. They were refined iteratively, so as to preclude previously observed errors from the agents.
All our prompts are designed to cause “chain-of-thought” reasoning from the agents. This means the prompts tell the agent to fulfill each sub-task through structured sequential steps; they include reflection points that encourage evaluation before proceeding; and they promote justifying agents’ choices (for example, the evidence gathering agents must justify why they think certain trends are referred to in a source). We could have simply chosen to use models that offer this reasoning capability out-of-the-box. However, our detailed prompting, which also causes agentic reporting of step-by-step progress, gives us greater observability and control over the process. Furthermore, the prompts incorporates safeguards (such as restriction on file access) aimed at further preventing hallucinations.
How does an agent know what a trend is?
This is a question we resolved through instructional prompting with illustrative guidance – for each trend type, we provided clear instructions on what to look for, illustrative examples of trends, and instructions on what not to look for.
A snippet from the prompt for identifying social trends:
Strictly only look for emerging behaviors, actions, preferences, values, and expectations among travelers.
Examples of these trends include:
- Conscious Tourism: Travelers seeking to minimize negative impacts and maximize positive contributions to destinations they visit
- Generational Shift: Changing travel preferences and behaviors as younger generations (Millennials, Gen Z, Gen Alpha) become dominant consumer groups
- Personalized Experiences: Increased demand from travelers for tailored itineraries and services based on individual preferences.
Remember these examples when looking for trends. What NOT to include (unless describing social behavior changes):
- Pure technology trends
- Business/industry trends
- Economic trends
- Infrastructure developments
- Policy changes
As stated above, a set of synthesis agents combine trends in listed in the interim result, to output the final list of trend names and descriptions.
The combination of synthesis agents is based on:
- Cross-source validation: when multiple sources reported similar findings, the agent consolidates them to create more robust, multi-sourced trends.
- Conceptual grouping: if the agent identifies conceptual similarities between the descriptions of trends that have different names, it combines them. For instance, the present trend of “Generational Travel Evolution” combines trends such as “Generational shift in travel preferences”, “Gen Z Travel Preferences”, and “Generational Shift in Travel” found in the interim result.
To obtain the current set of trends, we ran the model multiple times, each time slightly tweaking the instructions and/or the parameters of the agents (more on that below). After verifying the accuracy of the trend descriptions from the different trend sets, we further combined some trends and/or trend descriptions manually, and omitted some based on expert judgement of possible impact and on meagerness of sources.
Results of the trend survey
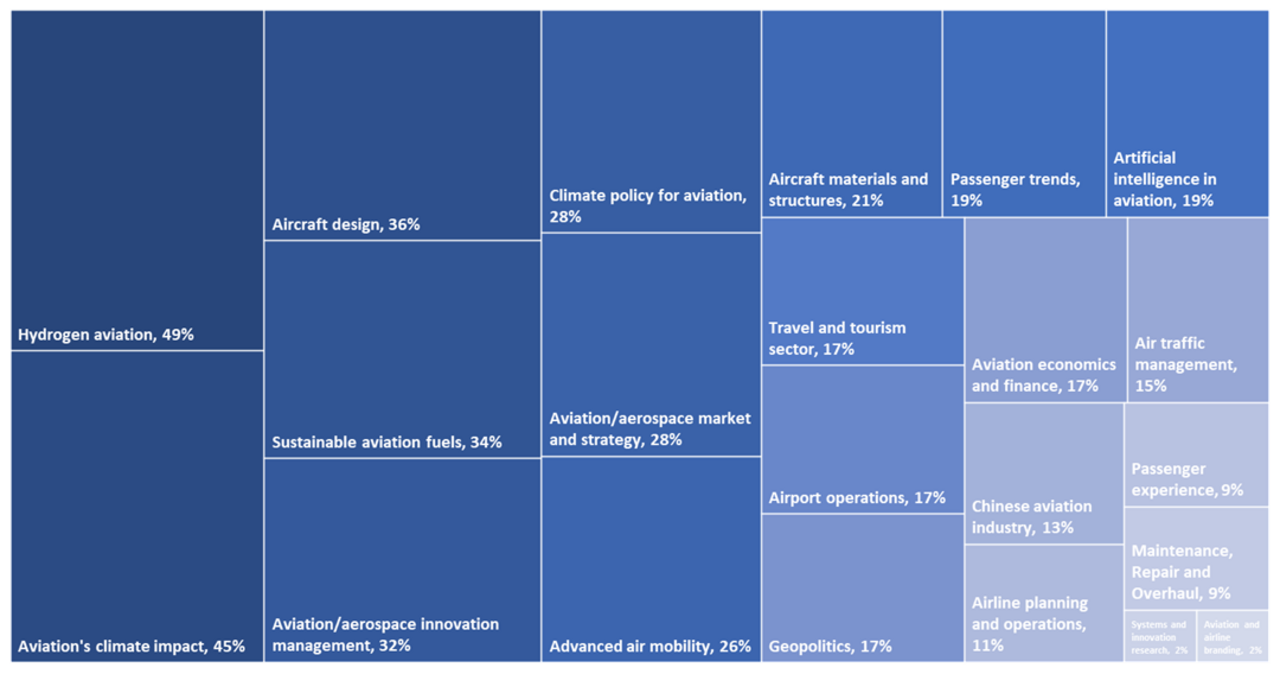
The survey we conducted to obtain trends that our agents could not identify, and to have experts score the trends on uncertainty and impact, received 47 completed responses. Respondents had designation such as CEO, Director of Strategy, Partner, Head of Engineering, Venture Manager etc. Ninety eight percent of our respondents were from Europe, with the other 2% coming from North America.
Multiple areas of expertise were represented in the survey; with Hydrogen aviation, Aviation’s climate impact, Aircraft design, Sustainable aviation fuels and Aviation/Aerospace innovation management being the top-five areas. Airline planning and operations, Passenger experience, MRO, Aviation and airline branding, and Systems and innovation research were the least represented areas.
Theoretical multi-agent system workflow
Existing and expert suggested trends
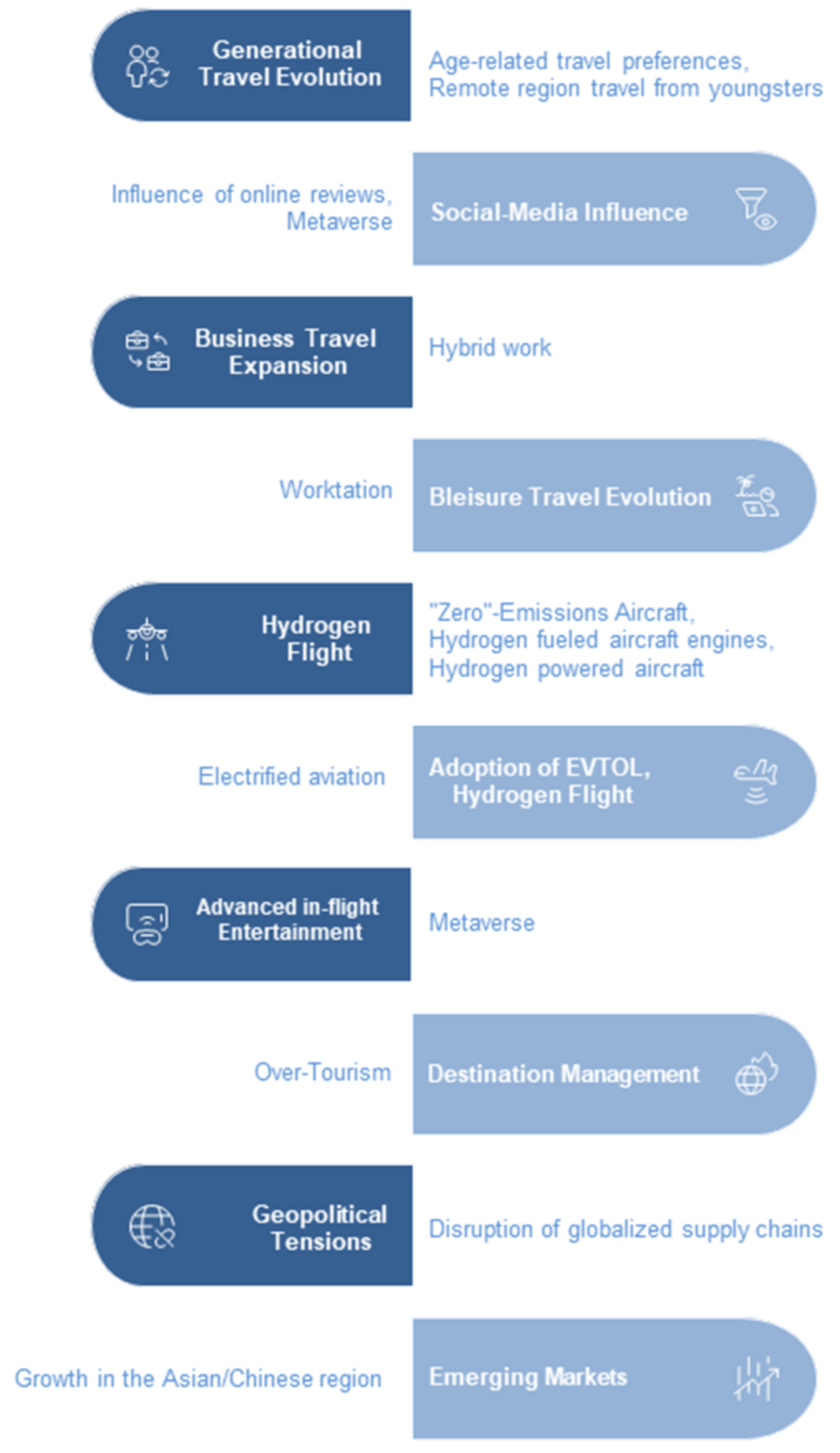
Among the trend suggestions we received, all but two were connected to existing identified trends. This suggests the agents have been able to considerably cover the relevant trendspace. The two trends we added to the list were “Expansion of High-speed Rail” and “Regulation of non-CO2 effects”. In total, we had 25 trends.
Existing trends in the balloons